
Real-Time Hand-Sign Language Recognition Using CNN and MediaPipe
Introduction
In a world where communication is key, barriers like language differences can pose significant challenges. One such challenge is bridging the communication gap for individuals who are mute or deaf and rely on American Sign Language (ASL) for communication. These individuals often face difficulties in interactions with those who are not familiar with ASL.
Thanks to advancements in artificial intelligence and deep learning, we have the opportunity to create systems that not only recognize and interpret hand signs but also promote inclusivity and understanding. Such systems can play a crucial role in not only helping the mute and deaf community by making communication more accessible but also promoting awareness to the general public.
This project develops a hand-sign language detection system that can recognize ASL alphabets in real time using OpenCV, MediaPipe, and Convolutional Neural Networks (CNN).
The complete source code of this project is available on my GitHub.
American Sign Language: Alphabets
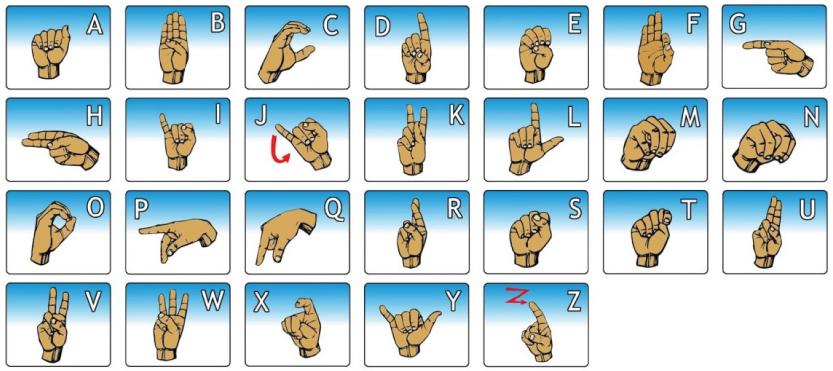
Here is a visual representation of the ASL alphabets from the sign language forum.
American Sign Language (ASL) is a complete, natural language that serves as the predominant sign language of deaf communities in the United States and most of Anglophone Canada. ASL uses hand gestures, facial expressions, and body language to convey meaning. For this project, we focus on recognizing the static hand gestures corresponding to 24 out of 26 ASL alphabets, excluding the letters J and Z, which involve dynamic gestures.
MediaPipe
MediaPipe is a cross-platform, open-source framework developed by Google for building multimodal machine learning pipelines. It provides highly efficient and customizable solutions for vision, text, audio, and generative AI tasks. This project uses Mediapipe's hand landmark model to detect the 21 hand-knuckle coordinates within the hand region.

Data Collection
The dataset for this project was created by capturing images from a live video feed using the computer's built-in webcam. OpenCV was used to interface with the webcam, while MediaPipe was used to detect hand landmarks. This combination allowed for precise hand tracking and cropping, ensuring that the dataset consisted of clear images of hand signs.
To create the dataset, run the script 'data_collection.py' and follow the instructions on the frame. Once you are ready with your first hand gesture, enter space to save the images. The variable 'dataset_size' can be modified to change the number of images captured per label which is then stored in the directory assigned by the variable 'img_dir'. If you are not working on ASL alphabets classification, then still this script can be used by modifying this piece of code to include your own labels instead of the characters A to Y.
for char in range(ord('A'), ord('Y') + 1):
if chr(char) =='J':
continue
else:
dir=os.path.join(img_dir, chr(char))
if not os.path.exists(dir):
os.makedirs(dir)
Each captured frame is then processed to identify hand landmarks and a bounding box is calculated around the hand to focus solely on the hand region. These cropped images are then saved in corresponding directories for each ASL alphabet, excluding 'J' and 'Z' due to their dynamic nature.
Data Collection Potential Improvements:
- Increasing Dataset Size: Collecting more images per alphabet can improve the model's accuracy and generalization. A larger dataset helps the model learn better feature representations, reducing overfitting.
- Using External Images: Incorporating images from the internet can augment the dataset, providing more examples and increasing the model's exposure to different hand shapes, sizes, and backgrounds.
- Capturing Images of Both Hands: Including images of both left and right hands can significantly increase the dataset's diversity and robustness. It helps the model learn variations in hand orientation and positioning.
Suggestion: If your frame doesn't open check the monitor number in 'cap = cv2.VideoCapture(0)'. If your laptop and phone are connected via Apple ID, chances are the phone camera switches on instead of the laptop's webcam. In that case, simply disconnect the Bluetooth option and try running the script again.
Data Preprocessing
Several preprocessing steps were performed in this project to ensure that the dataset was clean, standardized, and ready for the model training. First of all the hand sign images were loaded sequentially from the folders created in the previous step. Then each image was converted to grayscale to reduce the complexity and computational load of the model, as color information was not necessary for recognizing hand signs.
img=cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)if img is None:print(f"Warning: Could not read image {img_path}")continue
Next, the images were resized to a consistent size of 128x128 pixels. This standardization ensures that the input to the neural network has a uniform shape, which is essential for the training process.
img_resized = cv2.resize(img, (IMG_SIZE, IMG_SIZE))After resizing, the pixel values of the images were normalized to a range between 0 and 1 by dividing by 255. This normalization helps improve the convergence speed and stability of the training process by ensuring that the input values are on a similar scale.
img_normalized = img_resized / 255.0
data = data.reshape(-1, IMG_SIZE, IMG_SIZE, 1)
The class labels for each image were mapped to integer values to facilitate one-hot encoding, which converts the categorical labels into a binary matrix representation. This step is crucial for multi-class classification tasks, as it allows the model to output probabilities for each class.
from tensorflow.keras.utils import to_categorical
labels = to_categorical(labels)
Finally, the dataset was split into training and testing sets with a ratio of 80 to 20 using the 'train_test_split' function from the 'scikit-learn' library. This step ensures that the model's performance is evaluated on unseen data, providing a realistic measure of its generalization capability.
x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle=True, stratify=labels)The 'shuffle' parameter is set to 'True' as it ensures the data is randomly shuffled before splitting and it reduces bias. The split is stratified, meaning that the proportion of each class label is maintained in both the training and testing sets. This is important for ensuring that the model is trained and tested on a balanced representation of all the classes.
Model - Convolutional Neural Networks (CNN)
CNNs are particularly well-suited for image recognition tasks due to their ability to automatically and adaptively learn spatial hierarchies of features from input images. They are designed to recognize visual patterns directly from pixel images with minimal preprocessing making CNNs a powerful model for our hand-sign language detection project. Here is a basic layout of a CNN architecture.
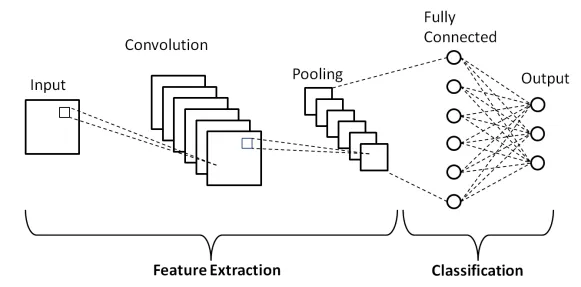
Model Architecture
The model architecture was designed using Keras and consists of several layers that help to extract features from images and make accurate predictions.
model = Sequential([
Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(IMG_SIZE, IMG_SIZE, 1)),
MaxPooling2D((2, 2),padding='same'),
Conv2D(64, (3, 3), activation='relu',padding='same'),
MaxPooling2D((2, 2),padding='same'),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
Input Layer: A 2D convolutional layer with 32 filters, each of size 3x3, and a Rectified Linear Unit (ReLU) activation function to introduce non-linearity into the model. A zero padding is added to the input image to keep the dimensions of the output feature map and the input equal.
First Pooling Layer: This layer performs max pooling with a 2x2 filter, which reduces the image dimensions from 128, 128, 32 to 64, 64, 32 by taking the maximum value in each 2x2 block. This helps in reducing the computational complexity and extracting dominant features.
Second Convolutional Layer and Pooling Layer: This layer has 64 filters of size 3x3, performing similar feature extraction operations as the first convolutional layer but with more filters. The pooling layer is similar to the previous layer, reducing the dimensions further.
Flatten Layer: This layer flattens the multi-dimensional feature maps into a 1D feature vector, which can be fed into the fully connected (dense) layers.
First Dense Layer: A dense (fully connected) layer with 128 neurons where each neuron is connected to every neuron in the previous layer, allowing the model to learn complex combinations of the extracted features.
Dropout Layer: Dropout is a regularization technique that randomly sets 50% of the input units to 0 at each update during training. This helps prevent overfitting by ensuring the model doesn't become too reliant on any particular set of features.
Output Layer: This dense layer has total neurons equal to the number of classes (in this case, 24 for ASL alphabets, excluding 'J' and 'Z'). The softmax activation function outputs a probability distribution over the classes, which is suitable for multi-class classification.
Model Training
With the model architecture defined and the data preprocessed, the next step is to train the Convolutional Neural Network. The training process involves iteratively updating the model's weights through backpropagation based on the loss computed from the training data. This will allow the model to learn the patterns and features necessary to correctly classify the hand signs.
history = model.fit(x_train, y_train,
epochs=20,
batch_size=32,
callbacks=[early_stopping, reduce_learning_rate],
verbose=1)
model.save('model.keras')The 'EarlyStopping' callback is used to prevent overfitting by halting training once the model's performance stops improving on a validation set. The 'ReduceLROnPlateau' callback is used to reduce the learning rate when the model's performance has stopped improving.
Saving the trained model for future use will save you a lot of time. This allows the model to be loaded and used for predictions with all the learned weights and configurations preserved.
Model Evaluation
The model displayed a 100% accuracy score on the training data with a small loss of 1.2647 x10-4 whereas the accuracy of the model on the testing data was 99% with a loss of 0.0242.
Image Classification on Live Frame
Real-time image classification poses unique challenges compared to evaluating a static test set that is quite similar to the training set. When working with live frames, the system must handle continuous input, process it quickly, and make accurate predictions, all without the luxury of preprocessing each image beforehand. This introduces issues such as varying lighting conditions, motion blur, and the need for immediate inference, which are not typically encountered when dealing with a pre-collected and curated dataset. Despite these challenges, this project performs all the preprocessing steps on the live frames and makes continuous predictions.
Solution Demo
The short demonstration video illustrates how the system accurately identifies some of the ASL alphabet characters in real-time and displays the predicted character above the bounding box.
Suggestions for Improvement
It is highly possible that duplicating this project might not result in 100% accurate predictions on your live frame capture. This can be improved by including more images of your hand in the dataset while keeping the lighting conditions similar. In the case of a significantly large dataset, the model layers and filters can also be increased, resulting in more accurate classification.
Conclusion
Developing a hand-sign language detection system that can recognize American Sign Language (ASL) alphabets in real-time is a significant step towards bridging the communication gap for the deaf and hard-of-hearing community. This project extends beyond just recognizing alphabets; it has the potential to be adapted for recognizing common and frequently used words in sign language. Whether you are a beginner or have some experience with machine learning, this project will enhance your skills and understanding of the model architecture and the preprocessing techniques.
Interested in seeing the full code and experimenting with this project yourself? Check out the complete code on my Github page.